
Racing to Language Model Parity and Deflationary Effects
As LLMs become commoditized, their specialization, the quality of integrated data, and compute units will be key differentiators in the AI landscape.

Race to Parity
Large Language Models (LLMs) are on the brink of a significant leap forward, with predictions suggesting they will achieve parity in capabilities within the next twelve months. Based on the transformer architecture, these auto-regressive models generate text one token at a time by predicting the next word given a series of previous words or prompts. This iterative process is fundamental to their operation and success.
LLMs rely on extensive datasets to hone their predictive abilities. Leading commercial and open-source models are trained on datasets such as Common Crawl, a massive repository of over 9 petabytes of data collected over 17 years, encompassing web pages, links, and metadata. Other essential data sources include WebText, BooksCorpus, Wikipedia, and social media. These rich and varied sources provide the context necessary for accurate predictions.

The vast volume of internet data and high-quality, human-generated data is crucial for effective training models. It is akin to light sweet crude oil—essential for refining into something valuable. LLMs risk performance degradation without data, known as the "Curse of Recursion" or model collapse, when models retrain on synthetic content, leading to "lossy" responses and diminished predictive quality. Studies show that repeated training on synthetic data without real data integration causes recursive degradation, where models progressively forget the original data distribution and lose generalization ability.
High-quality human-generated data is now scarce. To that end, commercial and open-source models will reach parity in GLUE metrics in roughly twelve months. Many engineers in the AI space geek out about new LLM features such as parameter size, context windows, token pricing, and inference speed. The future reality for model selection for everyday use will feel like selecting bottled water from your supermarket - Evian, Fiji, Aquafina, or Arrowhead. They all share common objectives, but there are slight differences in their benefits, brand, and packaging.
Furthermore, large enterprises' data and cloud gravity dominate their model selection criterion. The beauty of LLM commoditization is that the consumer wins. In addition, companies can purchase commercially supported LLMs with serious pricing pressure from open-source models. More on the closed and open-source debate later.
OpenAI, Meta, Mistral, and Anthropic invest heavily in cleaning up training data and fortifying their models RLHF. These could be future differentiators that disrupt the commoditization of LLMs. Many other companies focus on vertically integrated use cases trained on domain-specific corpus. They invest data and engineering resources to acquire and improve private corpus incorporated into public corpus to increase AI quality metrics further. Take Harvey.AI, founded by Gabriel Pereyra, a former Meta AI researcher, and Winston Weinberg, an ex-litigator from O'Melveny & Myers; Harvey.AI leverages advanced natural language processing to streamline various legal workflows, such as contract review, document analysis, and due diligence. Harvey.AI's solution builds on domain-specific models trained specifically for legal tasks. Designed and trained on OpenAI's GPT-4 language model, Harvey.AI's solution aims to reduce hallucinations in the legal space where accuracy is crucial to the rule of law. Abridge and Med-PaLM are for medical, TaxGPT is for US tax filings, and Sierra is for contact center support.
Tech is Deflationary
Technology has proven itself to be highly deflationary. I remember the day I got my Gmail account in 2004. Having 1 gigabyte of email storage was mind-blowing ($199 SD card for 1GB in 2004); today we deal in terabytes instead of gigabytes. Let's look at service inflation and tech deflation movements in the United States over the last 22 years. We've all benefitted from Moore's Law through our various technology cycles. AI scaling laws published in 2020 demonstrate the continued acceleration of AI model improvements, as reflected by data and prevailing research. Jensen Huang, CEO of Nvidia, proclaimed that model improvements will double every six months. To that end, AI will create strong deflationary effects.
{kind=link}
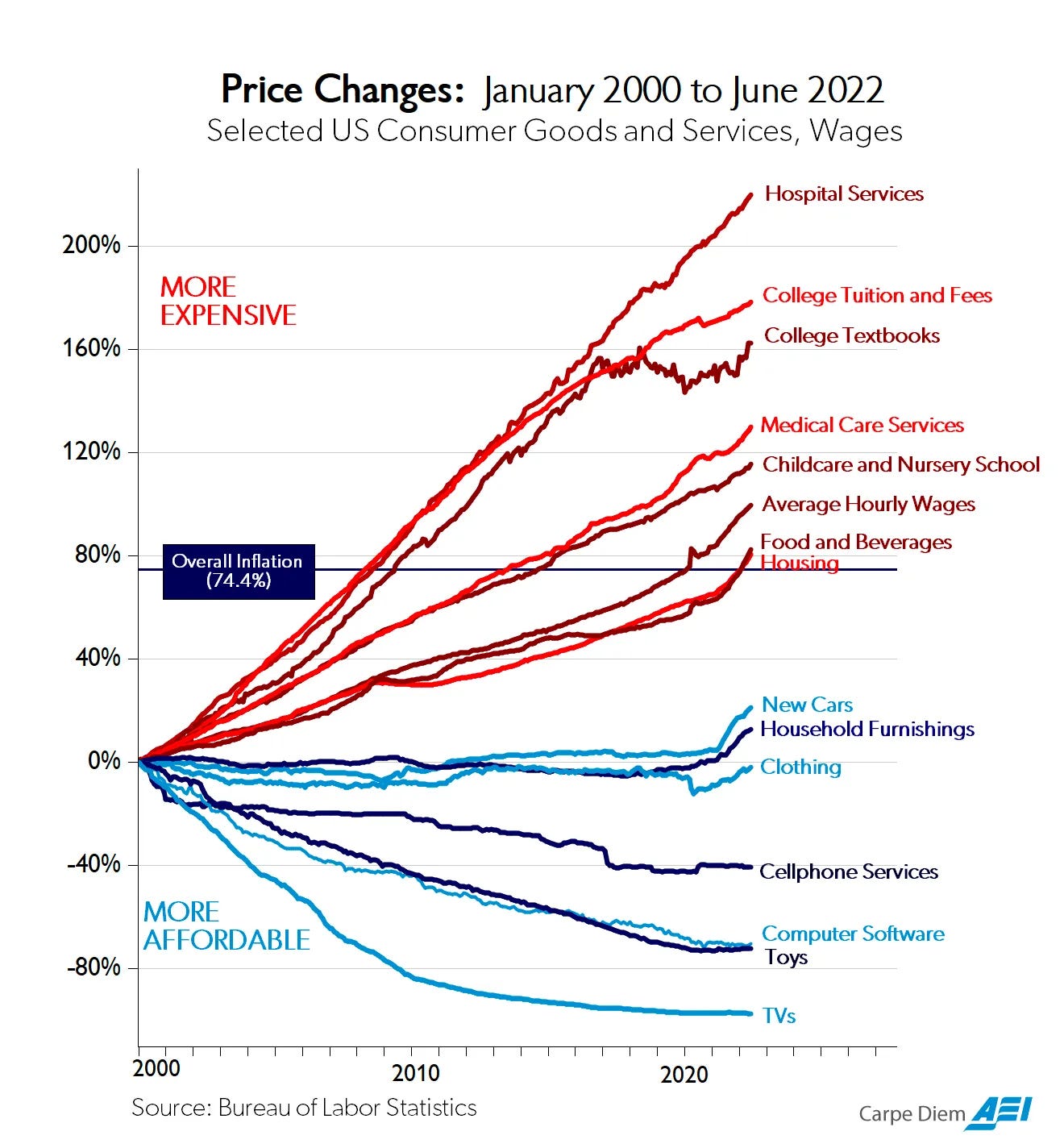
Deflationary AI
In the context of Moore's Law, which predicts that the number of transistors on a microchip doubles approximately every two years, leading to exponential growth in computational power, we can draw analogies to zero-sum and non-zero-sum games in AI and business efficiency.
A zero-sum game in AI-driven business optimization occurs when the benefits gained by one company through AI advancements are directly offset by the losses of another. If a company leverages AI to cut costs and gain a market advantage, the competition might suffer equivalent market share or profitability losses.
Conversely, a non-zero-sum game, akin to the spirit of Moore's Law, suggests that AI advancements can create new opportunities from freed resources that otherwise would have focused on rote cognitive activities. Companies benefit from created opportunities, increased efficiency, and reduced costs in this scenario.
The situation could also turn into a negative sum game. If every company adopts AI, the playing field levels and the initial competitive edge will diminish, similar to the adoption of PCs in the 1980s. The caveat emptor is for companies to deploy resources to find untapped opportunities strategically. When a company stays stagnant, AI will not be a differentiator when new products or services are not created. If everyone has AI, no one has AI.
Open Source AI FTW
Open-source language models will continue to drive down the cost of AI for everyone. See above, with models racing to parity, specializations to improve answer quality, and general commoditization of language models, a new class of commercially viable and rich companies will be built on the open sourcing of AI. Let's take the last decade of "as-a-Service" as an example; companies like Red Hat, MongoDB, Elastic, GitLab, Cloudera, and Automattic built their companies off open-source technologies. Collectively, the cross-section of these companies measures $78B in market capitalization. Open-source language models and AI benefit from community contributors' collective intelligence, allowing researchers and developers to improve and innovate on existing models. The power of peer review in the community setting creates transparency and trust. Meta raised the stakes for open-source with Llama3. Zuck committed to spend $35B-$40B to fund Meta's AI roadmap. The lion share of the spending focuses on building out the AI infrastructure.
There's a race to parity between open and closed-source language models, that will play itself out just like PC vs Macs, Android vs iPhones, or Linux vs closed OS’s. As LLMs become commodities, differentiation will accrue in AI specialization, and integrated compute units to run AI will be scarce. Integrating atoms and bytes to power AI comprises energy, compute hardware, networking, and language models. These will become economic units of measure in the coming generation.
I think i agree that if the main data set being used for the training is fairly static, that the models will converge fairly quickly capability wise and become more of a commodity. Of course the exact impact and end state as you mention is a bit undetermined. But If the models themselves converge capabilities wise, then is the "real data" owners who have the advantage because of their ability to train their deployed AI models? So in effect your differentiation would be your custom model (or at least custom trained model) that can create better solutions/answer for your domain (similar to the Harvey.AI use case you mentioned)?